[1] 30[1] 4[1] 8Formation théorique | 9h à 12h
2026-03-11
1. Script
C’est votre recette. On écrit ici pour pouvoir tout relancer plus tard.
2. Environnement
C’est votre garde-manger. Vos données et objets y sont stockés.
3. Console
C’est le four. Le code s’y exécute réellement.
4. Fichiers/Graphiques
C’est votre fenêtre sur le monde. On y voit nos dossiers et nos résultats.
Anatomie du code :
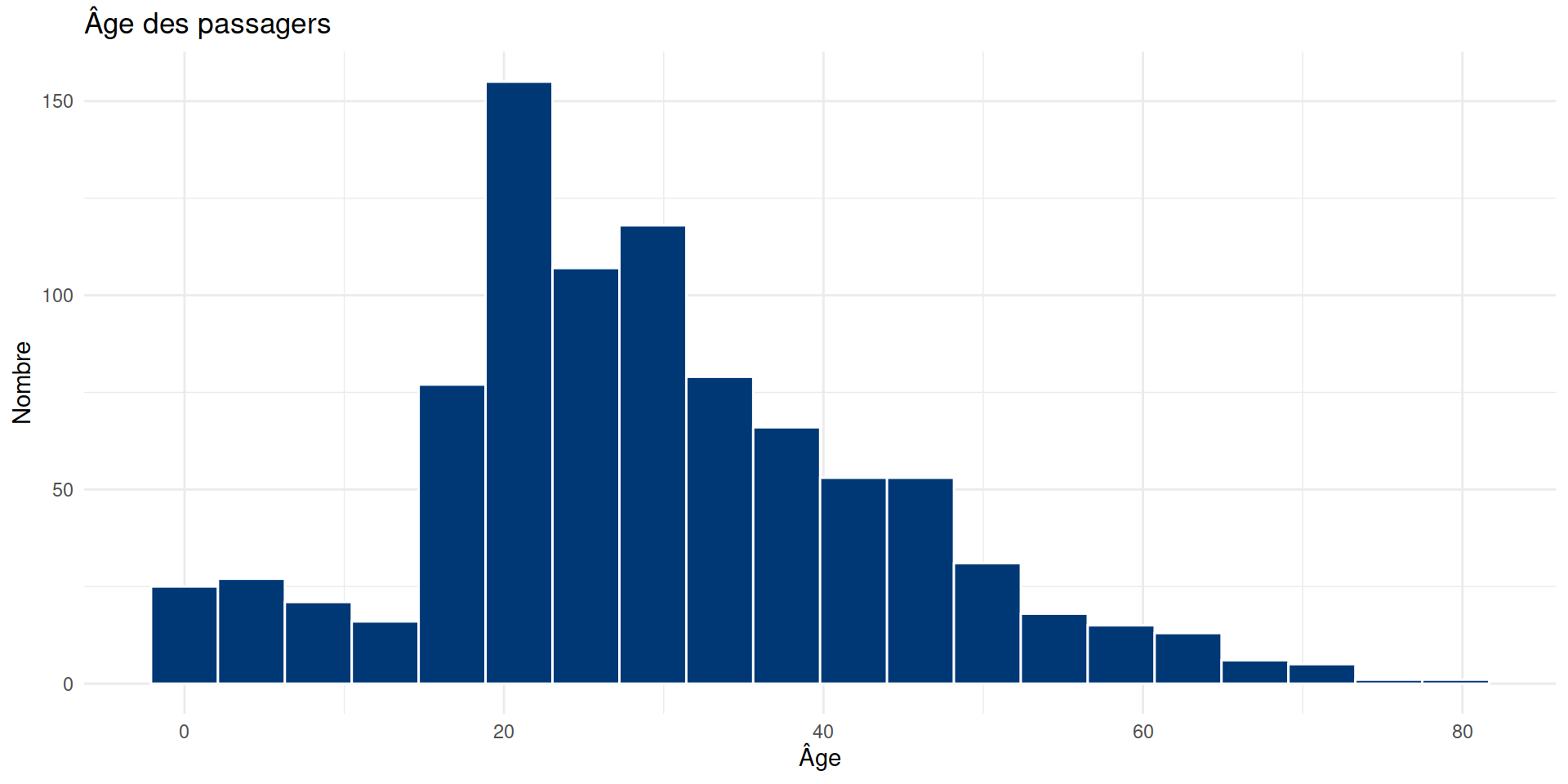
geom_histogram() : l’outil de distribution.bins = 20 : ajuste la précision.fill & color : l’esthétique.# RELATION ENTRE DEUX VARIABLES
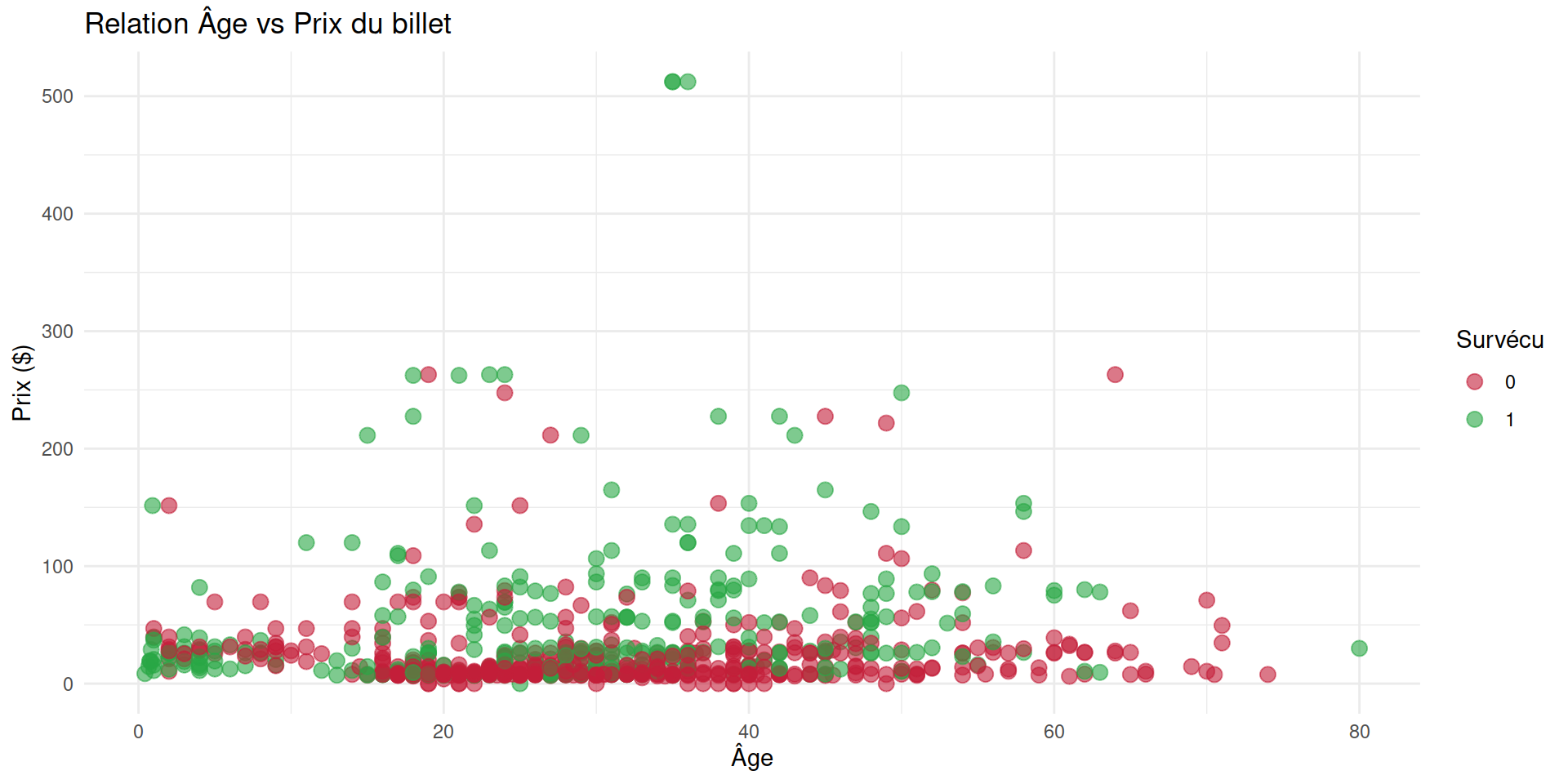
ggplot(titanic, aes(x = age, y = prix, color = factor(survie))) +
geom_point(alpha = 0.6, size = 3) + # points (alpha = transparence)
scale_color_manual(values = c("#C31E39", "#28a745")) + # couleurs manuelles
labs(title = "Relation Âge vs Prix du billet", color = "Survécu", x = "Âge", y = "Prix ($)") +
theme_minimal()Exemple de code fonctionnel :
library(wordcloud)
mots <- c("R", "Analyse", "Données", "Sociologie", "Science Politique",
"Statistiques", "Université", "Laval", "Recherche", "Tableau")
freq <- c(100, 80, 75, 60, 55, 50, 45, 40, 35, 30)
wordcloud(words = mots, freq = freq, min.freq = 1,
max.words = 50, random.order = FALSE,
colors = brewer.pal(8, "Dark2"))
Paramètres clés
À quoi ça sert ?
C’est un outil d’exploration rapide pour identifier les thèmes dominants d’un corpus avant de coder vos entretiens.